A/Bテストは、2つの変種(AとB)を比較して効果を評価する強力な実験手法です。しかし、実環境では曜日、ユーザーセグメント、地域など、テスト対象以外の「ノイズ(変動源)」が存在します。
これらの変動源を**ブロック因子(Blocking Factor)**として実験デザインに組み込む手法を、**ブロック化ランダム化デザイン(Randomized Complete Block Design: RCBD)**と呼びます。本記事では、このRCBDの設計から分析、サンプルサイズ計算、そして階層ベイズモデルへの拡張までを詳細に解説します。
1. 実験設計と分析の基本ステップ
ブロック因子を導入することで、実験のノイズを制御し、テストの精度(検出力)を大幅に向上させることが可能です。
基本的なワークフロー
- 処理(Treatment)の定義: 比較対象となるAとBの2グループを設定します。
- ブロック因子の特定: 応答変数に影響を与える可能性が高い要因(例: 曜日、デバイスタイプ)をブロックとして定義します。
- ランダム化と割り当て: 各ブロック内で、AとBをランダムに割り当てます。これにより、未知の交絡因子の影響を防ぎます。
- データ収集: 応答変数(クリック率、コンバージョン率など)を測定します。
- 効果の測定: ANOVA(分散分析)などを用いて、ブロック効果と処理効果を分離して評価します。
2. PythonによるシミュレーションとANOVA分析
ブロック化の威力を確認するために、Python(statsmodels, scipy)を用いたシミュレーション例を見てみましょう。3つのブロック(Block1〜3)を仮定し、各組み合わせでデータを生成します。
シミュレーションデータの例(一部抜粋)
Block Treatment Response
Block1 A 20.993428
Block1 A 19.723471
Block1 B 22.531726
Block1 B 26.158426
ANOVAによる結果解釈
モデル式: Response ~ C(Block) + C(Treatment)
Factor Sum of Squares df F-value p-value
C(Block) 396.775705 2 81.620843 6.214913e-12
C(Treatment) 65.947770 1 27.132269 1.938087e-05
Residual 63.195674 26 NaN NaN
- ブロック効果: p値がほぼ0であり、ブロック(環境要因)による変動が非常に大きいことがわかります。
- 処理効果: p値が約0.00002と有意です。ブロックの影響を統制したことで、AとBの差を明確に検出できました。
- 参考(ブロックを無視したt検定): もしブロックを無視して単純なt検定を行うと、p値は0.0549となり、有意水準5%で有意差なしと判定されてしまいます。これがブロック化最大のメリットです。
3. サンプルサイズの計算戦略
ブロックを導入すると誤差分散が小さくなるため、同じ検出力を得るために必要なサンプルサイズを削減できます。
基本的なサンプルサイズ計算式(ブロック無視の場合)
効果量や分散をもとに、各群に必要なサンプルサイズ nを計算します。

ブロック考慮時のサンプルサイズ削減アプローチ
厳密な公式は複雑なため、実務では以下のアプローチが有効です。
- 簡易近似(ルールの適用): ブロック内相関係数(ICC)が0.1〜0.3程度ある場合、通常の計算結果から総サンプル数を20〜40%削減して見積もります。
- ペアードデザイン近似: ブロック数が多く、各ブロック内でA/Bを1:1にする場合、ペアードt検定の計算式を近似として利用します。
4. 交互作用(Interaction)の考慮
ブロック(例: 曜日)によってA/Bテストの効果が異なる場合、交互作用をモデルに含める必要があります。
モデルの違い
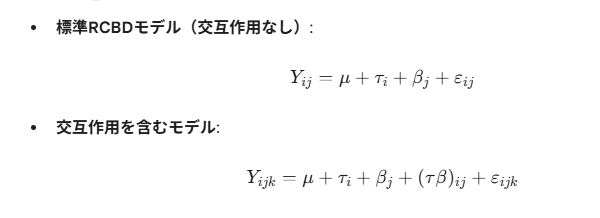
- ここで $(\tau\beta)_{ij}$ がブロックと処理の交互作用項です。
注意点: 交互作用を検出するためのサンプルサイズは、主効果(全体のA/B差)を検出する場合の約4〜6倍必要になります。実務上は、強い仮説がない限り交互作用の検証は「探索的」な位置付けにとどめるのが現実的です。
5. 階層ベイズモデルによる高度なアプローチ
サンプルサイズが爆発的に増える交互作用の問題を解決する強力な手法が、**階層ベイズモデル(Hierarchical Bayesian Model)**です。
部分プーリング(Partial Pooling)の力
階層ベイズモデルでは、各ブロックのパラメータを完全に独立させず、全体の分布から「部分的に情報を借りる(Shrinkage)」形で推定します。
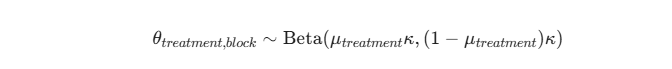
- データが少ないブロックは全体平均に引き寄せられ、外れ値の影響を緩和します。
- データが十分にあるブロックは、そのブロック独自の値が強く反映されます。
階層ベイズモデルのメリットとサンプルサイズ目安
頻度主義のANOVAと比較して、部分プーリングの効果により劇的なサンプルサイズの削減が期待できます。
目的頻度主義(ANOVA)の目安階層ベイズの目安
主効果のみ検出総 6,000 〜 10,000総 4,000 〜 7,000 (20〜40%削減)
交互作用も検出総 20,000 〜 50,000+総 8,000 〜 20,000 (50〜70%削減)